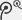上市公司
Securities industry5月20日,摩根士丹利正式发布了对英伟达下一代AI服务器架构Rubin平台(VR200 NVL72) 的机架物料清单(BOM)拆解研究报告。报告基于大量供应链实地调研和自下而上的精细化测算,对Rubin机架的整体定价、组件成本结构、ODM附加值变化以及供应链各环节的价值量变迁,进行了系统性的量化分析,成为市场重新定价AI算力经济学的关键参考基准。
报告的核心结论是:AI机架的价值正在经历前所未有的结构性扩散——从GPU“一芯独大”的单一叙事,正在演化为涵盖存储、连接、散热、封装等多个子赛道的“多极化增长”格局。

在理解大摩BOM拆解之前,需对Rubin平台的系统级设计有基本认知。Rubin平台并非单颗GPU的简单迭代,而是一个包含六款全新芯片、实现全栈协同的AI超级计算机体系。
六款芯片架构:Rubin平台以“极端协同设计”(extreme co-design) 为核心哲学,所有六款芯片——Vera CPU、Rubin GPU、NVLink 6交换机、ConnectX-9 SuperNIC、BlueField-4 DPU以及Spectrum-6以太网交换机——被设计为从底层开始就为彼此优化,而非将孤立优化的组件简单拼装成一个系统。
这种从单芯片思维向系统级思维的范式升级,正是黄仁勋此前在GTC 2026上宣称“AI工厂”理念的硬件实现基础。
Vera CPU的突破性意义:Vera CPU基于Arm架构,完整支持Armv9.2指令集,集成高速NVLink-C2C互连技术,实现与Rubin GPU之间1.8TB/s的惊人互连带宽,专为AI智能体及强化学习设计。黄仁勋在5月20日Q1财报会上透露,Vera CPU效率为传统CPU的两倍,带宽高达1.8TB/s,是PCIe 6.0的7倍性能,已向OpenAI、Anthropic、SpaceX AI及甲骨文云完成首批交付。
算力与内存:NVL72机架集成72颗Rubin GPU与36颗Vera CPU,系统内存总量达20.7TB HBM4(每GPU 288GB)与54TB LPDDR5X,GPU间NVLink 6互连带宽达260TB/s,峰值算力达3.6 Exaflops。
散热与电源:Rubin机架采用全液冷设计(无风扇),功耗超过200kW,需采用800V HVDC独立电源机架,散热量级和配电复杂度均为前代产品数倍。
量产时间表:预计2026年Q3首批出货,Q4正式进入大规模量产阶段。免费帮助投资人进行私募产品分析,100万起投优质产品推荐,欢迎添加微信Q8881961
大摩报告详细拆解了Rubin机架中各下游组件的价值量变化,揭示了AI产业链价值分布的结构性变迁。
关于内存价值暴增的深层逻辑(两点重要定性提示) :
其一,内存占比跃升至26%包含大量NAND闪存价值。根据大摩详细测算,VR200机架中约100万美元来自约8TB的3D NAND SSD(用于存储模型权重和推理缓冲区),NAND现货价格在2026年Q2已飙升至约125美元/GB;另约有43.2万至54万美元来自54TB LPDDR5X,HBM4则已包含在GPU价格(5.5万美元)中分摊。这一细节直接验证了本系列中闪迪、美光“NAND从商品变为战略资产”的叙事——单台Rubin机架8TB NAND用量乘以数万台的年出货量,其总需求规模已足以影响整个NAND行业的基本供需格局。免费帮助投资人进行私募产品分析,100万起投优质产品推荐,欢迎添加微信Q8881961
其二,大摩特别区分了两种内存采购情景:当NVIDIA自行采购SOCAMM内存模组并加价70%毛利转售时,机架ASP为780万美元;若超大规模客户选择自行采购SOCAMM内存,机架ASP将降至约670万美元。这一差异不仅关系到云厂商的CAPEX规划,也直接影响英伟达在该机架中的总盈利能力。
大摩BOM拆解所揭示的最大结构性洞见,在于AI数据中心的价值链条正在经历“级间扩散”。
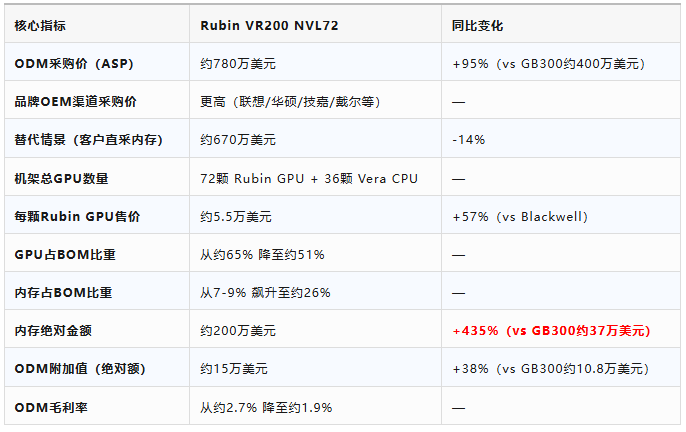
过去,人工智能硬件的价值高度集中于GPU这一单一环节——据大摩数据,GB200时代GPU占BOM比重高达65%。而在Rubin时代,虽然GPU的绝对价值仍然在上升(从约252万美元升至约396万美元,增幅57%),但其在总成本中的占比却从65%降至约51%。与之形成鲜明对比的是:
内存占比:从7-9%飙升至26%,成为第二大成本项;
ODM附加值的绝对额:逆市场预期增长约38%,从10.8万美元升至15.0万美元,推翻市场关于Rubin系统标准化将压缩ODM附加值的普遍判断;
PCB、MLCC、ABF等半导体上游组件的增速均超过80%(PCB甚至超过200%)。免费帮助投资人进行私募产品分析,100万起投优质产品推荐,欢迎添加微信Q8881961
这意味着:AI基础设施的投资回报率不再由GPU一方的定价和利润率决定,而是成为由内存、基板、散热、电源等多因子共同锚定的全局函数。在本系列已覆盖的众多公司中——美光、闪迪的直接受益方向最为清晰(内存占比从~9%跃升至26%,+435%增长),PCB厂商臻鼎科技、欣兴电子等将受益于233%的PCB增量,MLCC龙头村田制作所等受益于182%的MLCC增量,而台积电的CoWoS封装更是整个BOM中不可或缺的“基础设施税”。AI硬件的“赢家名单”正在大幅扩容。
大摩报告引用的200万美元内存成本中,绝大部分增量来自NAND闪存(约100万美元)、LPDDR5X(约44-54万美元)和HBM4。而NAND价格在2026年Q2已达到约125美元/GB的现货水平,这一涨幅主要来自本系列中闪迪、美光、SK海力士在2025年至2026年实现的定价权结构性转移。
但一个尚未被BOM量化讨论的关键变量是:NAND价格能否在2027-2028年维持这一高位?
从供给侧看,SK海力士将在2027年释放NAND新增产能,中国长江存储的10%以上市场份额仍在持续扩大。如果NAND价格在2027年进入高位整理甚至小幅回落,将直接映射到Rubin机架的内存成本基数上,也可能影响到云厂商自行采购SOCAMM的经济性——高存储价格越是持久,客户转向自采的动机越弱,英伟达加价70%的定价权反而越牢。因此,大摩区分两种采购情景的核心意义不在于判断“哪一种会发生”,而在于锚定内存价格这一动态博弈变量——大摩自身的BOM模型已经预设了这一外部条件可能沿基准情景发生漂移,但并未将其与云厂商自采SOCAMM的宏观经济阈值加以联合推理,为市场预留下了维度层面的分析空白。免费帮助投资人进行私募产品分析,100万起投优质产品推荐,欢迎添加微信Q8881961
大摩报告的BOM拆解基于当前的铜缆互联方案(Rubin NVLink Switch 6采用400Gbps SerDes驱动铜缆连接机架背板),但大摩在同期另文(TMT外资观点)中将CPO的产业化节奏视为未来数年的关键催化变量,明确指出:“NVIDIA NVL576及后续多机架架构视为CPO加速点,光引擎/GPU attach rate或从2-4升至17甚至35以上”。如果2027年之后的平台切换至CPO(光共封装)方案,BOM中的所有互联相关组件——如NVLink交换芯片、SerDes相关电路、PCB布线层数——都将发生系统性重构。届时,增量最快的受益者可能从铜缆时代的ABF/MLCC厂商切换至光模块/硅光材料产业链。
大摩报告在ODM价值部分给出了一个表面上矛盾的判断:ODM绝对附加值增长38%,但毛利率从2.7%降至1.9%,报告中特别强调投资者应关注绝对美元利润的增长而非利润率下降。
这是对于高ASP背景下硬件制造商业绩分析框架的核心分歧。当机架ASP从400万美元翻倍至780万美元时,即使毛利率下降,只要ODM能够保持同比例的业务量增长,绝对利润仍将大幅提升。以大摩测算为基准计算:GB300 ODM毛利额≈10.8万×2.7%≈2,916美元;VR200 ODM毛利额≈15.0万×1.9%≈2,850美元,两者近乎持平——因此毛利率下降在绝对额上的影响实际上被ASP涨幅基本对冲。但市场通常会线性外推“毛利率下滑=利润恶化”,而忽略了绝对利润增长的业务逻辑,这正是该部分引发的短期市场误读来源。本系列中希捷的“拒绝扩产”与本处ODM毛利率争论构成对称镜像——两者均源于周期股框架与结构性增长叙事之间的估值张力。免费帮助投资人进行私募产品分析,100万起投优质产品推荐,欢迎添加微信Q8881961
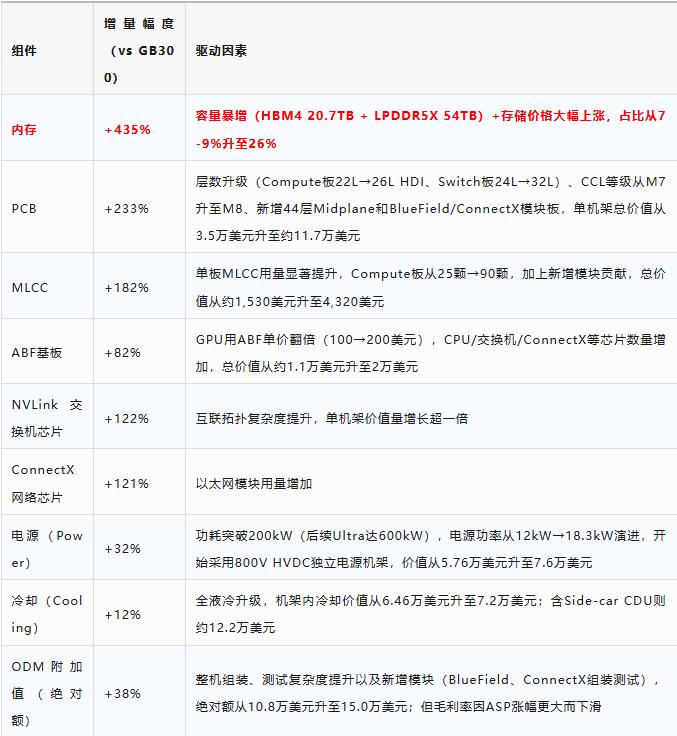
大摩Rubin BOM拆解报告发布次日(5月21日),多家机构同步上调英伟达目标价:
英伟达5月20日公布的Q1 FY2027财报创下816亿美元营收纪录(同比+85%),Q2指引910亿美元,远超预期。Vera Rubin量产节奏、CPU收入200亿美元目标和供应链承诺共同支撑了英伟达“AI工厂经济学”的框架
板块联动效应
Rubin BOM拆解消息发布前后,相关供应链标的集体获得市场关注:

大摩BOM拆解揭示的核心趋势是:AI计算的基础经济单元正在从单颗GPU转向整机架(Rack-as-a-compute-unit)。过去华尔街分析师习惯于按“GPU出货量×ASP”来线性推算英伟达的收入,而大摩报告展示的关键增量——780万美元的机架ASP和复杂子系统价值提升——表明英伟达的增长逻辑已经升级为系统级解决方案的全面输出。黄仁勋在GTC上反复强调的“AI工厂”理念,在BOM数字上获得了最坚实的量化支撑。免费帮助投资人进行私募产品分析,100万起投优质产品推荐,欢迎添加微信Q8881961
内存(HBM4+LPDDR5X+NAND)从7-9%跃升至26%的BOM占比变化,意味着存储已不再是基础设施的“辅助配料”,而是直接决定机架性能和整体TCO的战略资产。存储行业从“跟谁需求波动”向“决定需求能见度”的角色转换,将推动该赛道的估值体系从周期股向结构性增长股的重定价。这与本系列中美光、闪迪的核心叙事高度契合——AI服务器对NAND闪存的需求量是传统服务器的3倍,而Rubin单机架约100万美元的NAND价值(约8TB)仅为起步,后续随着模型规模扩大和推理上下文窗口增加,NAND用量还将进一步暴增。
大摩BOM分析中一个常被忽略的关键数字是:ODM附加值增长38%但毛利率从2.7%降至1.9%,引发市场短暂担忧。但报告中专门提醒,投资者应关注绝对美元利润的增长而非利润率下降——这是理解硬件制造行业在AI浪潮中的全新定位的核心。Rubin平台的整机组装和测试复杂度大幅提升,意味着ODM厂商的角色从“简单的螺丝刀式组装”升级为“深度嵌入的系统整合商”,其服务的不可替代性反而在增强。
200kW以上的机架功耗意味着传统AC供电和风冷方案都已达到物理极限。Rubin平台已经开始采用800V HVDC独立供电,并全面引入液冷(Side-car CDU约12.2万美元)。这两项技术门槛的提高,将在数据中心基础设施层面形成新的进入壁垒——只有具备高压供电和液冷工程能力的供应链伙伴,才能进入英伟达的下一代生态体系。
Rubin机架系统的复杂度之高——六款协同设计芯片、260TB/s GPU互联带宽、1.8TB/s CPU-GPU互联带宽、全液冷架构——意味着任何想要挑战英伟达的竞争者,不仅需要设计出与Rubin算力水平相当的GPU,还需要同时构建CPU、NVLink互联网络、DPU、以太网交换机和系统级散热方案的全栈能力。大摩报告的数据从另一个维度证明了英伟达的竞争护城河:“单点突破易,系统复制难”。正如大摩分析师Joseph Moore在5月21日维持英伟达为“Top Pick”时所指出的:“Vera Rubin按3Q交付和CY26 CPU收入200亿美元目标将继续压制ASIC分流叙事”。
摩根士丹利对Rubin平台机架BOM的精细拆解,将AI数据中心的硬件经济学向前推进了一大步。报告揭示的本质趋势是:AI机架的价值正在从GPU“独角戏”演变为内存、基板、互联、散热、电源共同分红的“合唱团”——其中内存以435%的暴增幅度和26%的BOM占比,最为突出地体现了“AI存储税”的结构性溢价,成为本系列分析中与闪迪、美光叙事高度契合的核心交叉验证点。
这份报告向市场传达的关键信息是:英伟达的增长故事不再仅仅是“GPU出货量×ASP”的线性叙事,而是AI计算基础设施的全面升级——从GPU到存储、从互连到封装、从散热到电源,整条AI硬件产业链的价值总量,正以前所未有的速度扩散和增长。以大摩测算为基准,从GB300的400万美元到VR200的780万美元,近乎一倍的机架价值量跃升,正是AI从“实验室工具”跃迁为“确定性基础设施”这一历史性范式转移的最微观、最可量化的映照。
本网站与微信公众号【用心小站研报中心】关联,新闻内容同步更新,公众号还有相关视频同时文章下方可评论,有问题可私信,有需要可同时关注公众号,获取金融领域实时资讯 ,每日推送,帮你规避投资风险、捕捉行业机会。

想追踪私募产品信息,获取最新资讯
微信扫码或加微信Q8881961解锁专属投资指南
✅ 加入高净值人群投资交流群,共享优质资源
保存扫描微信二维码,添加专业顾问微信:
✅ 1对1定制个人资金配比方案
评论专区
Comment area推荐产品
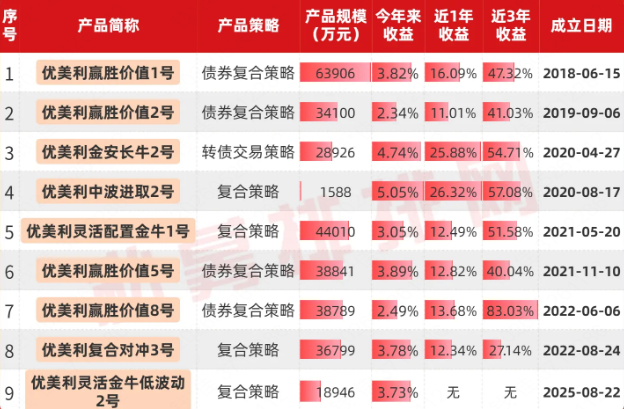
product新闻资讯
information



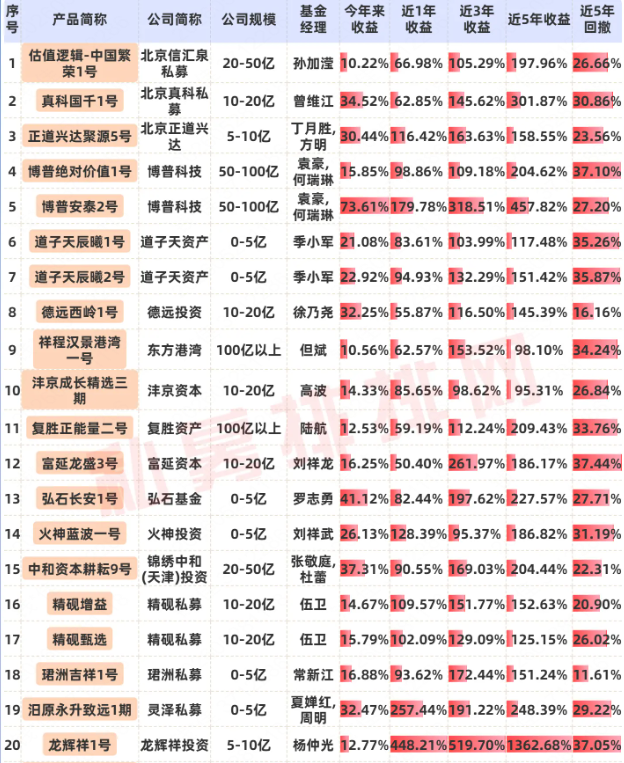





Securities industry





Bank financial management

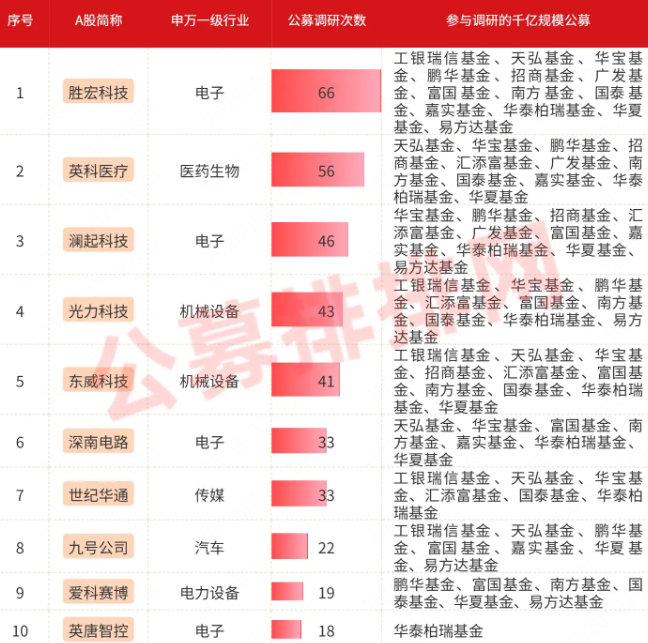
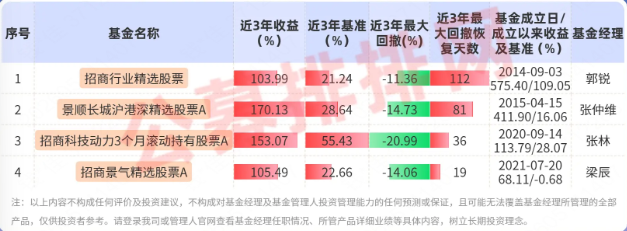



Trust financing













微信公众号
 官方微信
官方微信
 产品小程序
产品小程序